Capítulo IV
DISEÑO DE ARCHIVOS
1) Organización de Archivos
Uno de los conceptos básicos para diseñar sistemas de procesamiento de datos es el Archivo. Archivo es una serie de Registros relacionados. Un ejemplo es el archivo de inventario en él que hay un registro para cada artículo en existencia en el inventario de una empresa.
Un registro se compone de campos y todos los campos de un registro dado contienen información relacionada. Los campos que forman un registro de archivo de inventario pueden incluir lo siguiente:
- Clave o número del artículo
- Descripción del material
- Cantidad en existencia
- Precios, etc.
La información que los campos contienen de un determinado registro de inventario está relacionada, porque todos ellos se refieren a cierto artículo en existencia. Ver figura IV-1.
Los registros de un archivo se distinguen con una clave. La clave es un campo o una combinación de campos de un registro, que lo identifica exclusivamente.
El archivo de inventario es un archivo de datos maestros, o archivo maestro. El archivo maestro es un archivo de registros, cada uno de los cuales contiene información descriptiva, acumulativa y requerida para identificar individuo, cuenta, producto, precio, servicio u objeto al que se refiere.
El procesamiento de Datos consiste en aplicar datos de Transacción a datos maestros. Los datos de transacción son los que las operaciones diarias introducen. La venta de un artículo, por ejemplo, es un dato de transacción. Aplicar esa transacción especial al archivo maestro del inventario puede ser aislada en el archivo maestro el registro correspondiente al artículo, y disminuir en una unidad el contenido total de la existencia.
Para aplicar una transacción, hay que localizar el registro apropiado en el archivo maestro, buscando la clave de transacción en el archivo maestro. Esa operación de búsqueda consiste en igualar la clave de transacción con la clave del artículo maestro. La transacción se aplica al registro maestro que contiene la clave de igualación.
Existen dos formas para llevar a cabo esta operación; una de ellas consiste en aplicar las transacciones en orden aleatorio a un archivo maestro que se encuentre también en orden aleatorio. La característica distintiva del procesamiento aleatorio de datos, es que no se intenta algo para controlar el orden en que se aplican las transacciones a los datos maestros.
La forma más rudimentaria de llevar a cabo el procesamiento aleatorio de datos consiste en mantener también el orden aleatorio el archivo maestro. Entonces, para cada transacción hay que buscar en el archivo maestro hasta que se localice el registro maestro que tenga la clave de igualación, y entonces se puede aplicar la transacción. Esta es una técnica ineficiente.
Puede mejorarse la eficiencia del procesamiento aleatorio de datos si el archivo maestro se mantiene en algún orden conocido. El tiempo que se requiere para aplicar una transacción disminuye porque el registro maestro con la clave de igualación se puede localizar más fácilmente. Una forma de organizar el archivo maestro es por orden de secuencia. Un archivo ordenado en secuencia ordena sus registros por clave. Así, pues, un archivo de inventario por orden de secuencia, tendrá sus registros en secuencia, por número del artículo. El orden de secuencia más común es el del menor al mayor y, en esta presentación, se supone que un archivo ordenado en secuencia está en orden ascendente. Sin embargo, aunque el archivo maestro se ordene en secuencia, mientras no se intente controlar el orden en que se apliquen las transacciones, el tipo de procesamiento de datos seguirá siendo aleatorio. La alternativa del procesamiento aleatorio de datos es el procesamiento de datos en secuencia. En este tipo de procesamiento de datos, el archivo maestro siempre se ordena en secuencia y el archivo de transacciones se pone en el mismo orden de secuencia, antes de aplicar cualquier transacción a los datos maestros. La ordenación de un archivo en secuencia se llama clasificación.
El procesamiento de datos en secuencia tiene por objeto reducir el tiempo de búsqueda en el archivo maestro con la clave de igualación que permite aplicar la transacción.
La decisión de usar un método de procesamiento de datos aleatorio o en secuencia puede depender del equipo disponible para leer y escribir archivos. Una unidad de disco es un ejemplo de un mecanismo de acceso aleatorio.
Un disco es muy semejante a un disco fonográfico, a excepción de que el primero tiene un gran número de pistas circulares concéntricas en vez de una pista espiral de registro. Típicamente, una unidad de disco tiene una sola cabeza de lectura y escritura, montada en el extremo de un brazo semejante al de un tocadiscos. La información se registra en bloques en las pistas del disco, pero, a diferencia de la cinta, la localización de cada bloque en la pista es fija y, en consecuencia puede encontrarse. A fin de leer o escribir un bloque, el brazo se mueve hasta que la cabeza queda en posición sobre la pista apropiada, en cuyo punto espera la unidad, hasta que el bloque apropiado de la pista giratoria comienza a pasar debajo de la cabeza. El tiempo de movimiento del brazo se llama tiempo de acceso, y el tiempo de espera se llama tiempo de latencia.
Los dos objetivos principales que no hay que perder de vista en el diseño de registros son los siguientes:
- * Diseñar de tal manera los registros de un sistema, que la modificación del mismo sea lo más sencilla posible.
- * Disminuir el tiempo de corrida del sistema.
El tiempo de corrida tiene dos componentes; el tiempo de la computadora y el tiempo de entrada y salida. El tiempo de entrada y salida es el que requiere el dispositivo físico de entrada y salida para leer o escribir un registro. El tiempo de la computadora es el que se necesita para procesar en la memoria los registros.
Cuando se trata de ordenar datos en un registro, se procura conservar el tiempo de la computadora. Dado el tamaño de un registro, la forma en que se ordenan los datos dentro del mismo nada tiene que ver con el tiempo que se necesita para leer o escribir el registro. Sin embargo, la forma en que se ordenan los datos en un registro puede tener un efecto muy significativo en el tiempo que se requiere para procesar el registro.
Cuando se trata de la longitud del registro, se procura conservar el tiempo de entrada y salida. En términos generales, mientras más largo sea el registro, se necesita más tiempo para leerlo y escribirlo. No obstante, dentro de ciertos límites, mientras más largo es el registro, los datos se pueden ordenar más eficazmente dentro del mismo para abreviar el tiempo de la computadora.
Cuando se ordenan los campos de un registro, la consideración fundamental es la siguiente: ¿Cómo se va a usar este campo? Si hay que imprimir nombre y dirección en un informe, tal vez deben aparecer en el registro en forma editada. Si se trata de un campo en el que hay que hacer acumulaciones, tal vez se pueda hacer en forma decimal, ordenadas de tal forma que el punto decimal quede alineado con el punto decimal de los campos que se vayan a acumular y que sean suficientemente grandes para evitar que la información sobrepase los límites del campo. Si se trata de una clave que hay que probar con una gran variedad de valores, tal vez debe estar en forma binaria, y así sucesivamente. El resultado neto de esa orientación hacia el empleo de campos, es que en un sistema se ordenan primero los registros de los archivos que quedan más cercanos a la periferia del sistema (generalmente los archivos de informes). Luego se ordenan los registros de los archivos que se utilizan para producir los archivos de informes, después los registros de los archivos que se emplean para producir esos archivos de “segundo nivel”, y así sucesivamente, hasta que finalmente se ordenan los registros de transacciones y los del archivo maestro.
Los caracteres que forman un campo deben estar contiguos en el registro, a fin de que el campo no tenga que ensamblarse antes del procesamiento, o desensamblarse después de él.
Si se va a usar más de un campo como uno solo en una operación de procesamiento, se ordenarán en forma contigua en el registro. Por ejemplo, si varios campos se van a mover como un grupo del registro a otro lugar, situando los campos en el ordenamiento del registro, se podrá permitir que el cambio se haga con una sola instrucción de ejecución. En otros casos, los campos que se usen en común no solo deben colocarse contiguos en el registro, sino que se les debe dar un orden determinado. Si las claves de igualación y de transacción de un registro de transacciones se van a usar, por ejemplo, como clave de clasificación, deben estar contiguas.
Las recomendaciones anteriores de técnicas de ordenamiento de registros, no se pueden usar en el vacío. El ordenamiento de registros es sólo una consideración en el diseño general del sistema. Para ordenar eficazmente registros, hay que considerar la serie de corridas que emplea un archivo determinado al ordenar el registro para ese archivo. A menudo es necesario escoger una disposición de registros que sea menos que óptima para que una corrida determinada produzca la disposición óptima para el sistema. Para lograrlo, la disposición de registros debe ser más adecuada a las corridas que se usan con frecuencia, cuyo tiempo de corrida es muy prolongado y están limitadas por la computadora.
De lo anterior se puede concluir que mientras no se programe el sistema, es difícil decir si las disposiciones de registros incluidas en el diseño son las mejores. A medida que progrese la programación, se revelarán ciertas debilidades en esas disposiciones.
Con mucha frecuencia, cuando el diseñador del sistema considera la longitud de registros, piensa cómo podrá reducirla. No hay razón para reducir la longitud de registros sin otro motivo que el mero reducirla y, a menudo, hay más razones para aumentarla que para disminuirla. Antes de afectar la longitud de registros pensando reducirla, podría ser una buena práctica que el diseñador del sistema explicara por qué es conveniente reducirla.
En algunos casos la reducción consiguiente del tamaño de los archivos puede justificar que se reduzca la longitud de los registros. Por ejemplo, si reduciendo esa longitud se reduce el volumen de almacenamiento del medio que el usuario debe comprar y almacenar, se justifica que la longitud de registros se reduzca.
En archivos de cinta hay un gran incentivo para que cada archivo quede en un solo carrete. Para lograr que la computadora se utilice frecuentemente, conviene no detenerla esperando que se devanen las cintas. Esa consideración requiere que se asignen por lo menos dos unidades de cinta para cada archivo de varios carretes. Por lo tanto, incluir un archivo en un solo carrete puede significar que el usuario puede adoptar una configuración que requiera menos unidades de cinta o, por lo menos, que las unidades de cinta están libres para usarse en otros archivos, lo cual puede permitir que las corridas se consoliden, dando por resultado que el tiempo general de funcionamiento del sistema se reduzca. Ocurre lo mismo con los discos: los archivos más pequeños significan menos unidades de discos requeridas o mayor número de archivos manejados en una corrida.
En la argumentación anterior subyace el principio básico de que mientras haya más registros en el archivo, más significativa será reducir su longitud. La regla inversa es demasiado importante para que la expresemos explícitamente; mientras haya menos registros en un archivo, menos importante será reducir su longitud. Este es un punto que generalmente no se considera lo suficiente. Cuando los registros de un archivo son pocos, no es problema el volumen de almacenamiento. Por ejemplo, aún con una gran longitud de registros, el archivo todavía cabe en un carrete de cinta, con espacio de sobra. Así, pues, la única ventaja que se obtiene reduciendo la longitud de registros, es que se disminuye el tiempo de entrada y salida que se necesita para pasar el archivo.
Para subrayar la insignificancia del ahorro que se obtiene reduciendo la longitud de registros de un archivo que tenga muy pocos, hay que considerar lo siguiente: si la proporción efectiva de transferencia de datos de entrada y salida es de (s) segundos por caracter, entonces la proporción efectiva de transferencia (R), en términos de segundos por registro, es (s) multiplicada por la longitud del registro (c) expresada en caracteres por registro.
R = sc
Multiplicando (R) por el número (n) de registros de un archivo, da el tiempo de entrada y salida (T) del archivo.
T = snc
La cantidad (s) es una constante. (T) varía directamente de acuerdo con (n) y (c). Mientras más pequeña sea (n), un cambio de (c) afectará menos a (T).
Otro argumento en contra de la reducción de la longitud de registros de archivos relativamente cortos es que esa reducción solo disminuye el tiempo de entrada y salida y, en consecuencia, solo es provechosa cuando la corrida está limitada por la entrada y la salida. Muchas corridas, tal vez la mayoría, están limitadas por la computadora, y el tiempo de funcionamiento puede reducirse realmente, aumentando la longitud de registros.
Quizás la razón más poderosa para aumentar la longitud de registros más allá de los límites impuestos por cualquier preocupación por la facilidad de procesamiento, sea la posibilidad de consolidar los archivos de poco volumen.
2) Descripción de Archivos
A continuación se describe el contenido de los tres archivos del sistema: CLTS, PROV y ARTI.
Archivo “CLTS” (Clientes)
PERIODICIDAD DE GRABACION DIARIA LONGITUD DEL REGISTRO 126 bytes NUMERO DE REGISTROS 50 TAMAÑO DEL ARCHIVO 30 bloques
Este archivo contiene los datos del cliente, tales como nombre, dirección, colonia, población y teléfono. Contiene además un campo para datos estadísticos donde se almacenará la variable A-1 con el importe total facturado a cada cliente por mes.
Archivo “PROV” (Proveedores)
PERIODICIDAD DE GRABACION DIARIA LONGITUD DEL REGISTRO 126 bytes NUMERO DE REGISTROS 20 TAMAÑO DEL ARCHIVO 1.5 bloques
Este archivo contiene los datos de los proveedores, tales como nombre o razón social del proveedor, dirección, colonia, población y teléfono. Contiene además un campo para datos estadísticos, donde se almacenará la sumatoria del importe total comprado a cada proveedor (en la variable B1).
Archivo “ARTI” (Artículos)
PERIODICIDAD DE GRABACION DIARIA LONGITUD DEL REGISTRO 210 bytes NUMERO DE REGISTROS 500 TAMAÑO DEL ARCHIVO 45 bloques
Este archivo contiene todos los datos de los artículos en las variables C1, C2$, C3, C4, C5, C6 y C7. Contiene además la variable C8$ para conservar la estadística de ventas de 30 días anteriores a la fecha en que se facture, la variable C8 donde se acumularán las unidades vendidas por día y la variable C9 donde se acumularán las unidades compradas por día.
3) Descripción de Informes
R-1) Catálogo de Clientes. Contiene primeramente la fecha y los encabezados, después el número del cliente, el nombre, la dirección, la colonia, la población y el teléfono; al final se indica el total de clientes. Ver figura IV-1, página 30.
R-2) Catálogo de Proveedores. Contiene primeramente la fecha y los encabezados, después el número del proveedor, la razón social o nombre de la empresa, la dirección, la población y el teléfono; al final se indica el total de proveedores. Ver figura IV-2, página 31.
R-3) Catálogo de Artículos. Contiene primeramente la fecha y los encabezados, después la clave del artículo, la descripción, el precio de costo, el precio de venta, la existencia, el stock mínimo y el stock máximo; al final del catálogo se indica el total de los artículos. Ver figura IV-3, página 32.
R-4) Factura. Este reporte contiene primeramente el encabezado, después los datos del cliente, el número de factura (o de folio) y la fecha; en seguida los artículos facturados conteniendo, clave, descripción, cantidad, precio unitario y el importe, al final se indica el total de las unidades facturadas y el importe total de la factura. Ver figura IV-4, página 33.
R-5) Póliza de Compra. Este reporte contiene primeramente el encabezado, después los datos del proveedor, el número de la póliza y la fecha; en seguida los artículos adquiridos conteniendo, la clave, la descripción, la cantidad, el precio unitario de costo y el importe, al final se indica el total de unidades y el importe total de la póliza. Ver figura IV-5, página 34.
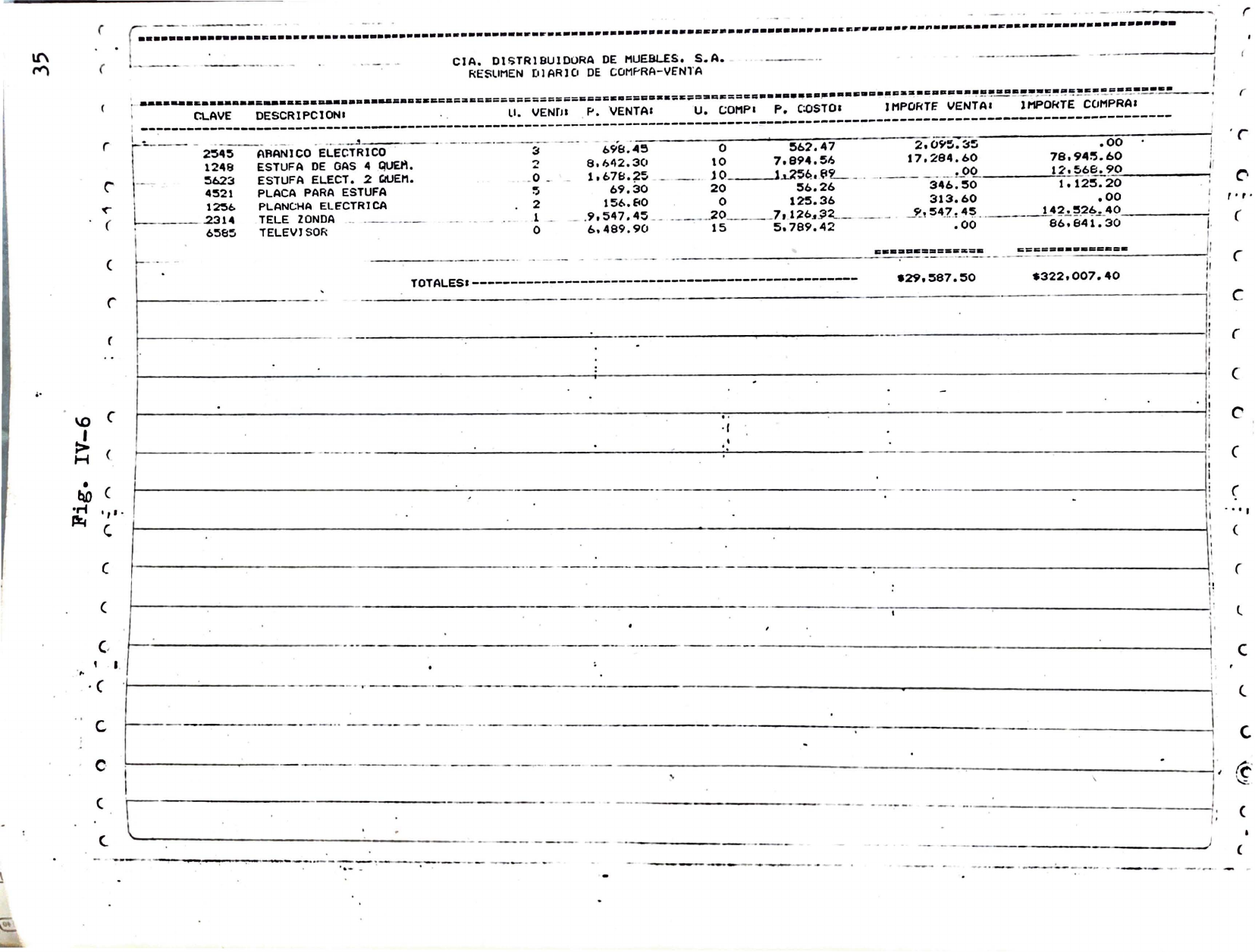
R-6) Resumen Diario de Compra-Venta. Este reporte contiene además del encabezado y la fecha, un listado de los artículos que tuvieron movimiento ese día, ya sea en venta, en compra, o en ambos casos; al final, los totales generales por compra y por venta respectivamente. Ver figura IV-6, página 35.
R-7) Resumen Mensual Cliente-Proveedores. Este reporte contiene primeramente el encabezado y la fecha, después un listado de los clientes ordenado de mayor a menor por el importe de su compra mensual, calcula además para cada cliente a que porcentaje del total corresponde su importe. Después aparece el listado de los proveedores, ordenado también por su importe de mayor a menor, también se calcula para cada proveedor a que porcentaje del total corresponde su importe; al final se encuentran los totales generales de las ventas acumuladas y de las compras acumuladas. Ver figura IV-7, página 36.
R-8) Valorización del Inventario. Este reporte tiene después de la fecha y el encabezado, un listado de todos los artículos, teniendo para cada uno, su precio de costo, su precio de venta, su porcentaje del margen de utilidad, la existencia a esa fecha, la valorización de la existencia a precio de costo y la valorización de la misma a precio de venta. Al final, el total general de la valorización a precio de venta y el total general de la valorización a precio de costo. Ver figura IV-8, página 37.
R-9) Artículos Mayores que el Máximo. Este reporte contiene primeramente el encabezado y la fecha; después un listado de los artículos cuya existencia se encuentra por arriba del valor del stock máximo; para cada artículo en este caso, aparece su clave, descripción, existencia, stock mínimo, stock máximo y la diferencia entre la existencia y el límite máximo. Ver figura IV-9, página 38.
R-10) Artículos Menores que el Mínimo. Este reporte contiene primeramente el encabezado y la fecha; después un listado de los artículos cuya existencia se encuentra por debajo del valor del stock mínimo; para cada artículo en este caso, aparece su clave, descripción, existencia, stock mínimo, stock máximo y la diferencia entre la existencia y el límite máximo. Ver figura IV-10, página 39.
R-11) Artículos a Resurtir. Este es uno de los reportes más importantes del sistema, ya que permite a la persona indicada, tomar decisiones en base a los datos que proporciona este reporte. Primeramente tenemos el encabezado y la fecha y posteriormente un listado de todos los artículos del archivo, cada uno con su clave, descripción, existencia, stock mínimo, stock máximo, venta promedio, duración estimada y una sugerencia. Ver figura IV-11, página 40.
La venta diaria promedio se calcula sumando la venta diaria de los treinta días anteriores a la fecha de que se trate (dato contenido en la variable C8 del archivo ARTI), y dividiéndola entre treinta. La duración estimada hasta agotar existencias se calcula dividiendo la existencia entre la venta diaria promedio. Para determinar la “sugerencia”, se está siguiendo la siguiente regla: si la duración hasta agotar existencias alcanza para más de quince días, entonces no se sugiere nada; si alcanza para quince o menos, pero para más de tres, entonces se sugiere RESURTIR; pero si alcanza para tres días o menos, se sugerirá RESURTIR URGENTE.
Las figuras IV-1 a IV-11 son las impresiones de muestra de cada reporte, generadas por el sistema corriendo sobre datos reales. De ellas, solo la figura IV-6 (mostrada arriba) está incluida en esta digitalización.